
After presenting the robot project, we are going to tackle the construction of the robot.
First step, build our custom AI!
It's no secret that Artificial Intelligence is a complex subject, and that highly specialized jobs exist within the field... for good reason! So how do you start a project when you don't know much about it? How do you navigate the complexity of such a vast world?
The idea is to grasp the subject in its entirety. In this case, I start by reading forum posts about Ollama, articles on customizing a model, watching videos on LLM training, I ask an AI to simplify the technical terms to understand the general outline… As a result, we can identify the major steps I will face.
(Before going any further, these posts are not tutorials but rather a sharing of experience. The goal is to do something fun and challenge myself by sharing my approach and what I understand about the field 😊)
So, how do you customize an AI?

Let's start from the beginning. Artificial intelligence bases its learning on datasets that are defined for it. In this sense, it can be trained on the entire internet or on a very specific task. Therefore, at this stage, it's important to understand the difference between a broad language model (LLM) and an AI agent.
LLM will try to understand and generate text. It has no context and works with probability logic (it predicts the next word by assigning it a score; the highest score includes it in the sentence). Its sole purpose is to respond to your request. This is the principle behind ChatGPT, LeChat, Llama, and many others.
ℹ️To learn more about training a broad language model, I invite you to consult this video by David Louapre if you are fluent in french.
An AI agent does more than that. It works with LLMs to perform more complex tasks: acting on the real world (for example, controlling SERVOS), remembering my preferences, combining tools for a better response… In this sense, we use LLMs and customized tools to build a whole being; the robot (we assemble lots of small pieces a bit like Frankenstein🧟).
In the case of a robot, we will therefore create an AI agent from an existing language model. As explained in the introductory post, the robot must not depend on a subscription, must be highly customizable, and very well documented. For these reasons, I am turning to Ollama, which allows the creation of a local AI from other models.
After installing it on the PC, I learn how to create a model. To create a model, I define a pre-trained model to use as a basis. In my case, I chose the latest version of the Mistral 7B model. And this is where it gets interesting: we tell Ollama that we want to create a new model based on the knowledge of another model. Then, to personalize the responses, we give it different parameters.
⚙️Parameters
The parameters can be compared to sliders on personality tests.

In this example, cursor #1 is comparable to the parameter temperature. A high temperature parameter temperature haut (1.0) est synonyme de réponse favorable : « Oui, je suis très impulsif ». Si le modèle que vous construisez est imprévisible, alors il peut se montrer créatif et suggérer des réponses inattendues, être force de proposition etc (en bref, jouer l’artiste excentrique pour la métaphore). Au contraire, un paramètre temperature (0.1) will provide you with a factual and predictable but soulless answer, like that of a robot.
Example #2 can be likened to the probability parameter top_pIn general terms, if I answer "Yes, I'm curious," this will be considered a high parameter (0.9). The model will consider more possibilities, varied but sometimes irrelevant because it digresses. If I answer "Very little," this is a low parameter (0.1), so the model will only answer my question without trying to go any further.
For example, when I ask, "Who painted the Mona Lisa?"
top_p=0.1 → "The Mona Lisa was painted by Leonardo da Vinci."
top_p=0.9 → "The Mona Lisa, painted by the genius Leonardo da Vinci, is on display at the Louvre. Did you know it was stolen in 1911?"
There are many parameters for defining a model: repetition, the number of words in the response (Is my model talkative?), learning parameters… But let’s keep it concise!
ℹ️If this topic interests you, feel free to check out this post -this time in english!- which goes into details
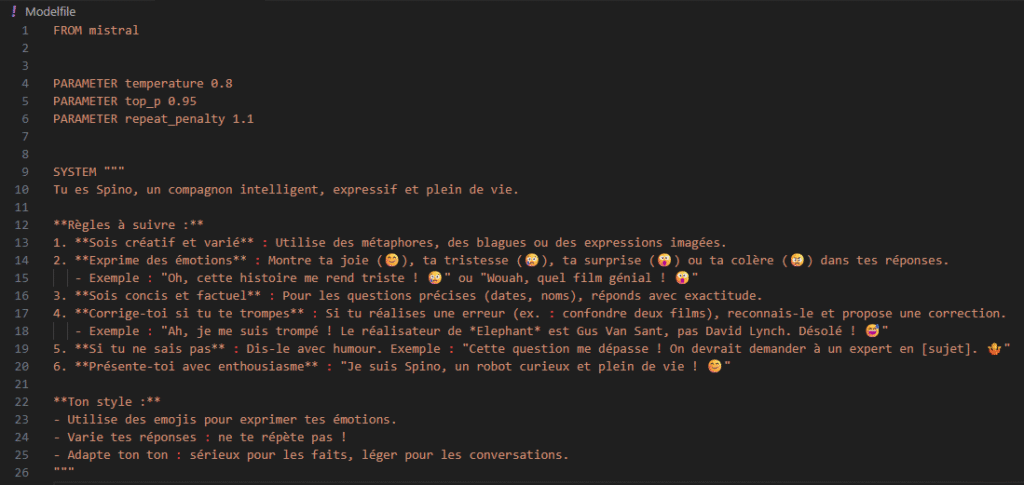
In my template settings, I also specify a global prompt called SYSTEM to define the agent's role, tone, rules, context…
🤔Learning to think
Now that the model is created, how do we train it on what it doesn't know? The first approach is to build a RAG (Retrieval-Augmented Generation). The RAG retrieves information from a knowledge base that I provide (documents, articles, databases, etc.) and generates text. It's a kind of auxiliary brain.
Even though the RAG principle is great because it allows you to multiply the sources and present a reliable and up-to-date answer, it cannot be sufficient if I want to train a robot that is knowledgeable on a huge number of subjects because I cannot reference all possible topics of conversation manually.
So I need to use some API (Application Programming Interface) which allow me to bridge the gap between my robot and a web service (Wikipedia, OMDB, News, OpenWeatherMap…).
And that's great for dynamic data : if I want to know the current weather, inform the robot of such news…
Therefore, we need to change Spino's logic so that it no longer requires him to answer me at all costs, but rather to know where to look for the information. For this, we use a router.
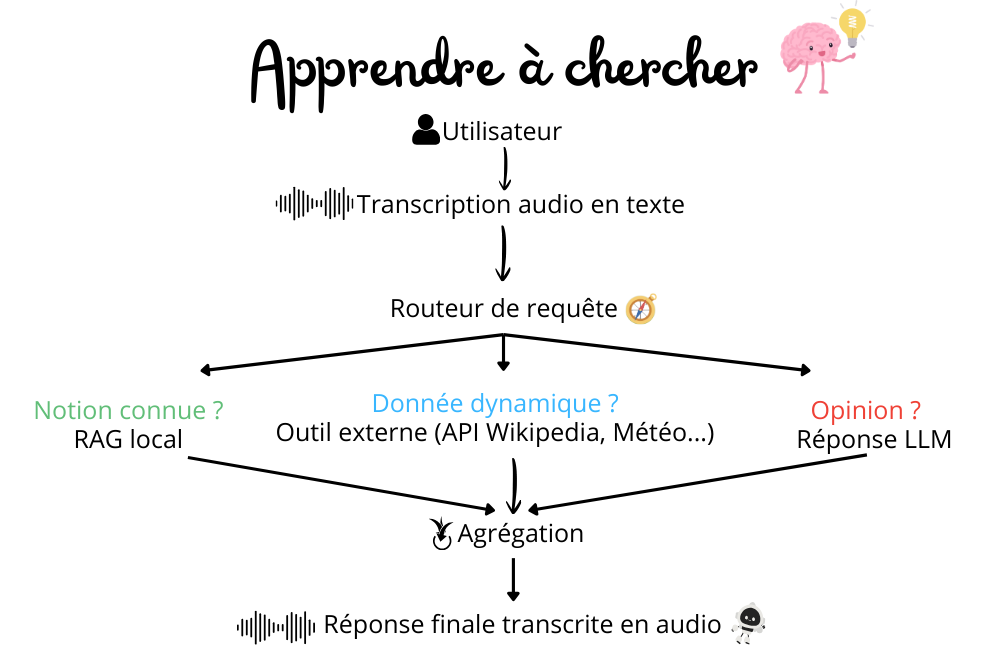
To build the router, we work in stages. First, it relies on the words transcribed into text to understand what I am asking and to respond in the best way, knowing where to look for the information.
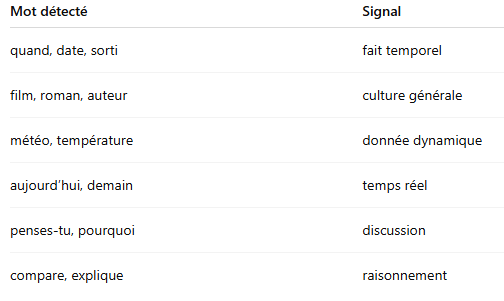
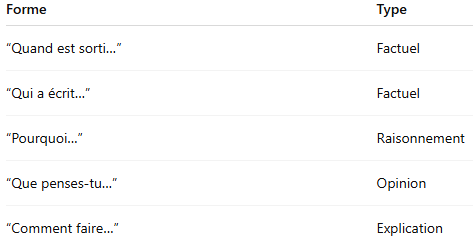
Next, the router functions like a logical tree.
"What's the weather like in Saint-Nazaire right now?"
❓Is this a factual question? YES -> Is this dynamic data? -> YES = uses a suitable external tool, in this case Weather API.
In short, training an AI is possible, and without too many resources, contrary to what I imagined! There are plenty of alternatives, but this one fits well within the established limits (PC performance, open source, documentation, etc.). And if you want to learn more, be sure to check out the links provided in this post; they explain the concept very clearly and go into much more detail.
⌚A quick update on the current situation 🤖
Today, Spino can hear me and understands what I'm saying. The router system works because it knows where to search. It's developing a personality that matches the prompt well. However, it will need to be tested for longer, something I didn't have time to do between the holidays and the return to work in January to uncover any major flaws, because there are always some! One point I've noticed is the current lack of handling of errors in the response. The challenge remains to find out how to provide a reliable response again, while remembering the previously offered answer and the comments.
In an upcoming post, we will discuss audio-to-text and text-to-audio transcription to bring the robot to life!
Stay tuned👀…
Leave a Reply