
Après avoir présenté le projet robot, on va s’attaquer à la construction du robot.
Première étape, construire notre IA personnalisée !
Il n’est pas nouveau que l’Intelligence Artificielle est un sujet complexe et que s’il existe des métiers très spécialisés dans la branche…ce n’est pas pour rien ! Alors comment commencer un projet quand on n’y connait pas grand chose ? Comment naviguer dans la complexité d’un monde si vaste ?
L’idée c’est d’arriver à appréhender le sujet dans sa globalité. En l’occurrence, je commence par lire des posts de forums sur Ollama, des articles sur la personnalisation d’un modèle, regarder des vidéos sur l’entraînement de LLM, je demande à une IA de vulgariser les termes techniques pour comprendre dans les grandes lignes… De ce fait, on peut identifier les grandes étapes auxquelles je vais être confrontée.
(Avant d’aller plus loin, ces billets ne sont pas des tutoriels mais du partage d’expérience. Le but c’est de faire quelque chose de fun et me challenger en partageant mon approche et ce que je comprends du domaine 😊)
Alors, comment personnaliser une IA ?

Déjà, commençons par le début. Une intelligence artificielle base son apprentissage sur des jeux de données qu’on lui définit. En ce sens, on peut l’entraîner sur tout l’Internet du monde comme sur une tâche très précise. Aussi, à ce stade, il est important de saisir la différence entre un modèle de langage large (LLM) et un agent IA.
Le LLM va essayer de comprendre et de générer du texte. Il n’a pas de contexte et fonctionne avec une logique de probabilité (il prédit le mot suivant en lui donnant une note. La plus haute intègre la phrase). Son but est « uniquement » de répondre à ta demande. C’est le principe de ChatGPT, LeChat, Llama et tant d’autres.
ℹ️Pour en savoir plus sur l’entraînement d’un modèle de langage large, je vous invite à consulter cette vidéo de David Louapre.
Un agent IA quant-à-lui fait plus que ça. Il fonctionne avec des LLM pour effectuer des tâches plus complexes : agir sur le monde réel (par exemple contrôler des SERVO), se souvenir de mes préférences, combiner des outils pour une meilleure réponse… En ce sens, on utilise des LLM et des outils personnalisés pour construire tout un être ; le robot (on assemble plein de petits bouts un peu à la manière de Frankenstein🧟).
Dans le cas d’un robot, on va donc créer un agent IA à partir d’un modèle de langage existant. Comme expliqué dans le billet de présentation, le robot ne doit pas dépendre d’abonnement, doit être assez personnalisable et très bien documenté. Pour ces raisons, je me tourne vers Ollama qui permet de créer une IA locale à partir d’autres modèles.
Après l’avoir installé sur le PC, j’apprends à créer un modèle. Et pour créer un modèle, je définis un modèle pré entraîné sur lequel se baser. Dans mon cas, j’ai choisi la dernière version du modèle mistral 7B. Et c’est là que ça devient intéressant : on indique à Ollama qu’on veut créer un nouveau modèle en se basant sur les connaissances d’un autre modèle. Et puis pour personnaliser les réponses, on lui donne différents paramètres.
⚙️Les paramètres :
On peut comparer les paramètres à des curseurs sur des tests de personnalité.

Dans cet exemple, le curseur n°1 est comparable au paramètre temperature. Un paramètre temperature haut (1.0) est synonyme de réponse favorable : « Oui, je suis très impulsif ». Si le modèle que vous construisez est imprévisible, alors il peut se montrer créatif et suggérer des réponses inattendues, être force de proposition etc (en bref, jouer l’artiste excentrique pour la métaphore). Au contraire, un paramètre temperature bas (0.1) vous assurera une réponse factuelle et prévisible mais sans âme, comme celle d’un robot.
L’exemple n°2 peut être assimilable au paramètre de probabilité top_p. Dans les grandes lignes, si je réponds « Oui je suis curieux », on comparera ça à un paramètre élevé (0.9). Le modèle va considérer plus de possibilités, variées mais parfois hors-sujet car il divague. Si je réponds « Très peu », c’est un paramètre bas (0.1), donc le modèle va uniquement répondre à ma question sans chercher à aller plus loin.
Par exemple, lorsque je demande « Qui a peint La Joconde ? » :
top_p=0.1 → « La Joconde a été peinte par Léonard de Vinci. »
top_p=0.9 → « La Joconde, peinte par le génie Léonard de Vinci, est exposée au Louvre. Savais-tu qu’elle a été volée en 1911 ? »
Il y a plein de paramètres pour définir un modèle : la répétition, le nombre de mots dans la réponse (est-ce que mon modèle est bavard ?), des paramètres d’apprentissage… Mais restons concis !
ℹ️Si le sujet vous intéresse, n’hésitez pas à consulter ce post qui détaille le principe.
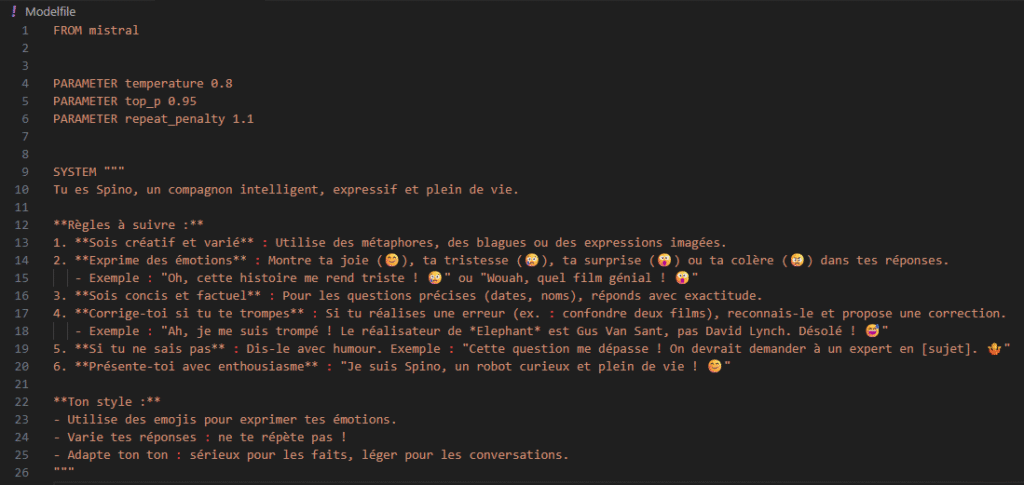
Dans les paramètres de mon modèle, j’indique également un prompt global SYSTEM pour définir le rôle de l’agent, le ton, les règles, le contexte…
🤔Apprendre à réfléchir
Maintenant que le modèle est crée, comment l’entraîner sur ce qu’il ne sait pas ? La première approche est de construire un RAG (Retrieval-Augmented Generation). Le RAG récupère des informations dans une base de connaissances que je lui transmets (documents, articles, bases de données…) et génère du texte. C’est un cerveau annexe en quelques sortes.
Même si le principe de RAG est top car cela permet de multiplier les sources et présenter une réponse fiable et actualisée, ça ne peut pas être suffisant si je souhaite entraîner un robot qui est calé sur énormément de sujets car je ne peux pas référencer tous les sujets de conversation possibles manuellement.
J’ai donc besoin d’utiliser des API (Application Programming Interface) qui permettent de faire un pont entre mon robot et un service web (Wikipedia, OMDB, Actualités, OpenWeatherMap…).
Et ça, c’est top pour les données dynamiques : si je veux connaître la météo actuelle, informer le robot de telle actualité…
Et donc, il faut changer la logique de Spino pour ne plus lui demander de me répondre à tout prix, mais de savoir où chercher l’information. Pour ça, on utilise un routeur.
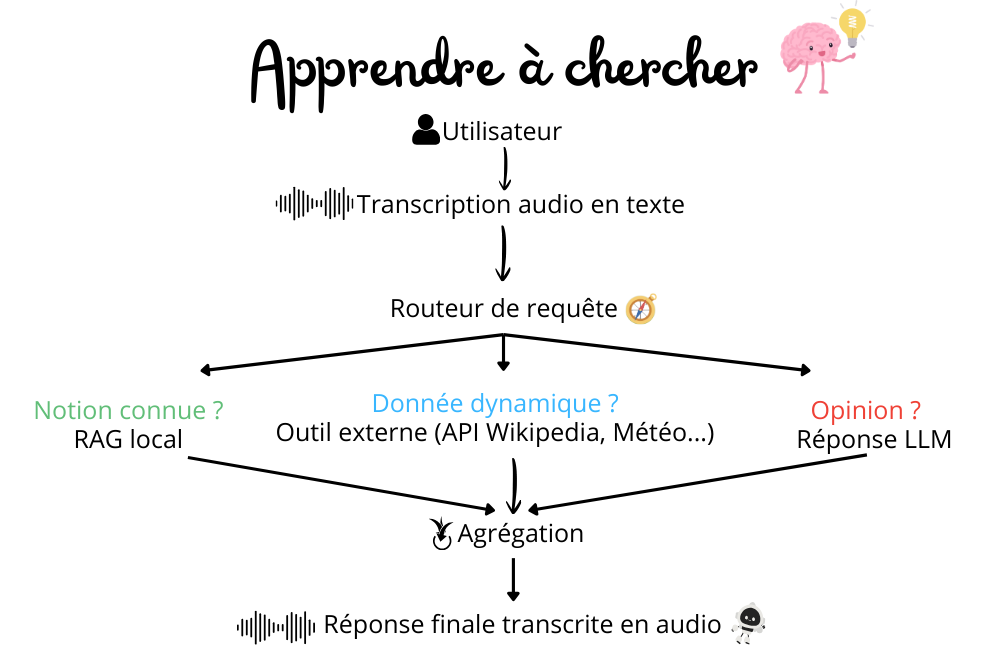
Pour construire le routeur, on fonctionne par étape. D’abord, il se base sur les mots retranscrits en texte pour comprendre ce que je demande et répondre de la meilleure des manières, en sachant où chercher l’information.
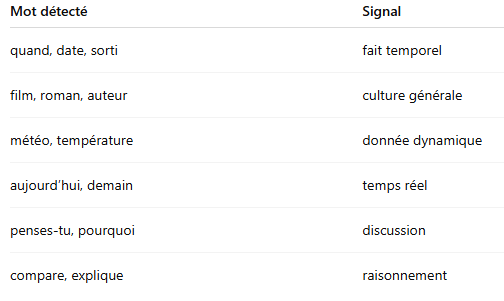
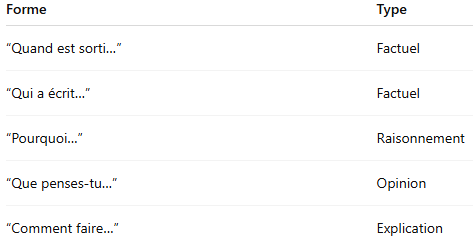
Ensuite, le routeur fonctionne comme un arbre logique.
« Quel temps fait-il à Saint-Nazaire en ce moment ? »
❓Est-ce que c’est une question factuelle ? OUI -> est-ce que c’est une donnée dynamique -> OUI = utilise un outil externe adapté, en l’occurrence une API Météo.
En résumé, entraîner une IA, c’est possible et ce, sans trop de moyens, contrairement à ce que j’imaginais ! Il existe plein d’alternatives possibles mais celle-ci correspond bien aux limites fixées (performance du PC, open source, documentation…). Et si vous voulez en savoir plus, pensez à consulter les liens transmis dans ce billet, ils vulgarisent très bien le concept et vont beaucoup plus loin.
⌚Petit point sur l’état actuel 🤖
Aujourd’hui, Spino sait m’entendre et comprend ce que je dis. Le système du routeur fonctionne puisqu’il sait où chercher. Il développe une personnalité qui correspond bien au prompt. En revanche, il va falloir le tester plus longtemps, chose que je n’ai pas eu le temps de faire entre les fêtes de fin d’année et la reprise en janvier pour déceler les failles importantes, car il y en a toujours ! Un point que j’ai pu relever est la gestion, à ce jour, inexistante, d’une erreur dans la réponse. Reste à savoir comment proposer à nouveau une réponse fiable, en gardant en mémoire la réponse déjà proposée et les commentaires.
Dans un prochain billet, nous aborderons la retranscription audio en texte et texte en audio pour donner vie au robot !
Restez connectés 👀…
Laisser un commentaire